Virtualization Obfuscation
Virtualization obfuscation is designed to make static analysis boring, noisy, and slow. Instead of compiling logic directly into normal machine code, an obfuscator translates it into bytecode for a custom virtual machine. The binary then contains a VM interpreter, bytecode, and an opcode dispatch mechanism. The original logic is still there, but it is hidden behind the interpreter’s state.
A classic virtualized program often has this shape:
VM interpreter
pc = bytecode_base
stack = local_vm_stack
while true:
opcode = *pc
handler = dispatch_table[opcode]
jump handler
handler
mutate VM stack / VM pc / memory
jump dispatcher
This post applies that model to 0000/challenge-0 from the Tigress challenge
set and recovers the protected one-argument hash-style computation.
The Challenge
IDA shows that main parses one decimal argument with strtoul, calls the
virtualized routine, and prints one unsigned integer.
In Tigress challenge terms, family 0000 is one level of virtualization with
random dispatch. challenge-0 is one of the stripped binaries in that family:
feed it an integer, recover the deobfuscated source for the transformed
uint64_t -> uint64_t function.
❯ ./0000/challenge-0 1000
14550994578197470752
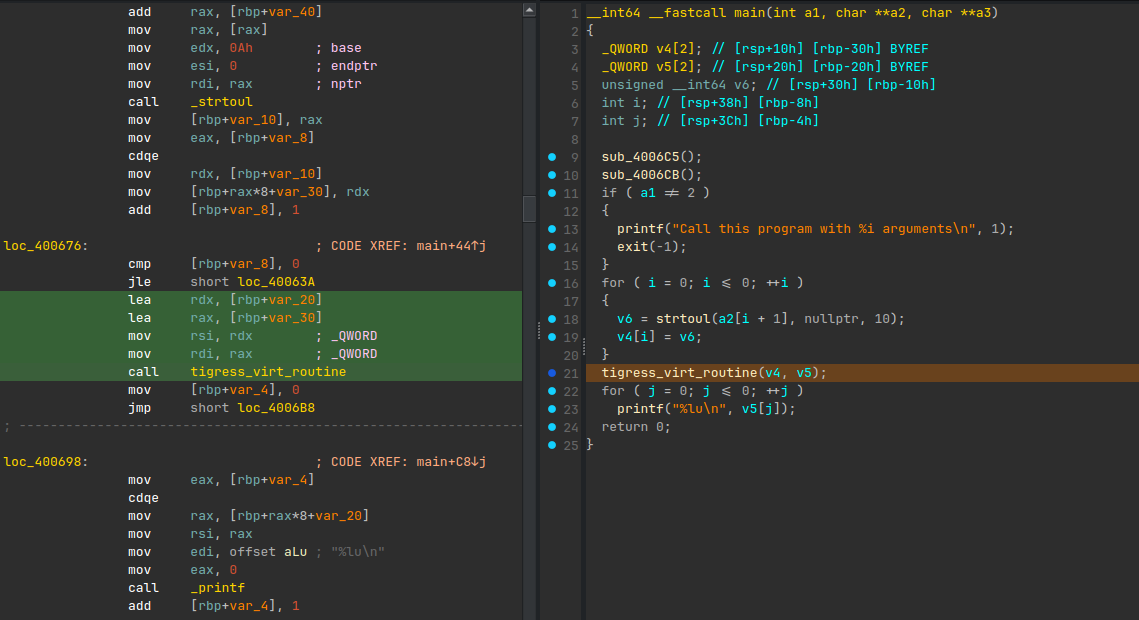
tigress_virt_routine graph view:
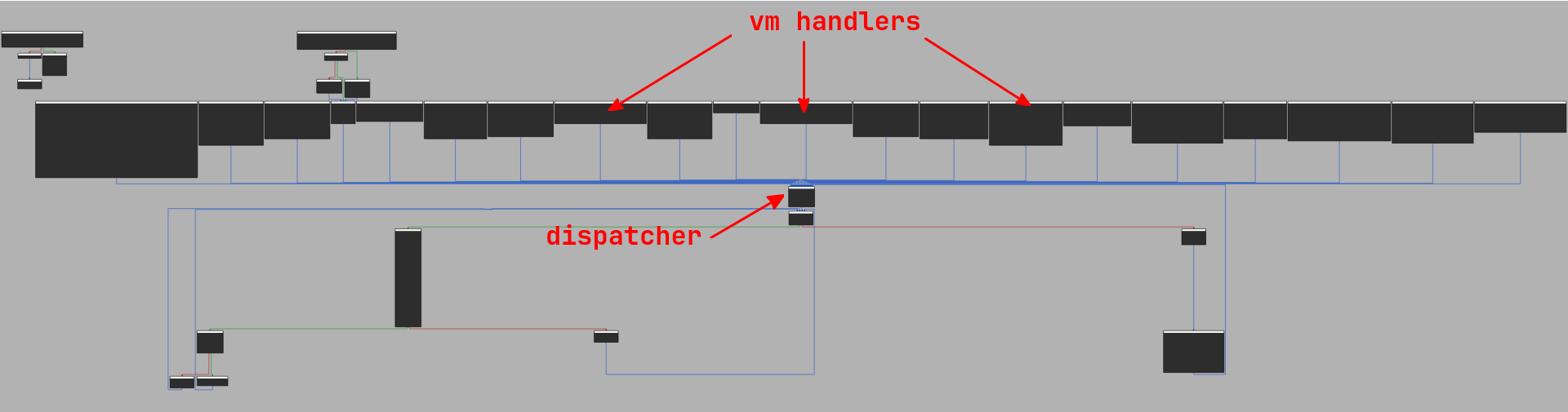
Example VM handlers:
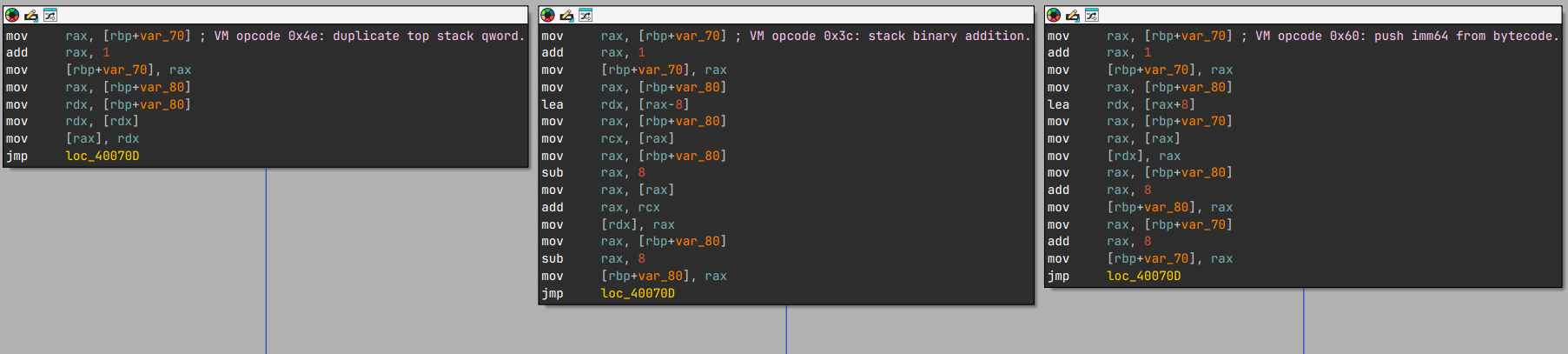
After further exploration:
VM entry: 0x4006d1
VM bytecode: 0x602060
VM dispatch table: 0x602400
VM return handler: 0x400c35
The dispatch table has 21 entries:
struct dispatch_entry {
uint64_t opcode;
uint64_t handler;
};
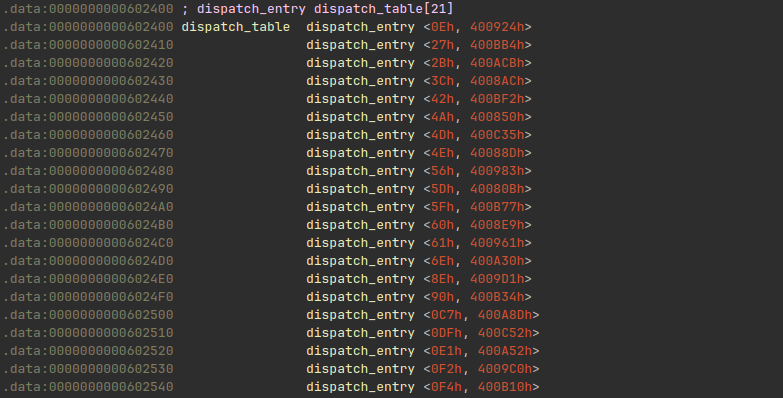
The table recovered from the binary is:
0x0e -> 0x400924
0x27 -> 0x400bb4
...
0xf4 -> 0x400b10
The VM keeps its own VM PC and stack pointer in the native stack frame:
[rbp - 0x70] = VM bytecode PC
[rbp - 0x80] = VM stack pointer
The dispatcher reads the opcode at the VM PC, performs an interpolation search on the table, loads the handler address, and jumps to it indirectly. We now know the wrapper, entry point, bytecode, dispatch table, and return handler. What remains is the source-level computation represented by the bytecode.
Manual Devirtualization
Manual devirtualization usually involves:
- Recovering the bytecode.
- Recovering the virtual opcode handlers.
- Writing a custom bytecode parser.
- Writing a model for every virtual opcode.
- Lifting the bytecode to C, LLVM, Python, or an IR.
- Simplifying the lifted logic.
While that works, the riskiest part is handler modeling.
If opcode 0xc7 multiplies stack values, opcode 0x2b shifts right,
and opcode 0x4d returns, each detail must be modeled exactly. One wrong width,
sign extension, stack adjustment, or memory access can poison the expression.
Since the VM runs a fixed computation over a single uint64_t, a full custom lifter
is heavier than necessary. Instead, we can execute the native VM and ask a
symbolic execution engine what expression reaches the output buffer.
What is Triton?
Triton is a dynamic binary analysis framework. It executes machine instructions while tracking both concrete values and symbolic expressions.
Concrete execution tells us the current value of a register or memory location. Symbolic execution tells us how that value was computed from earlier inputs. If a program computes:
out = ((x + 0x1234) * 7) ^ 0x55;
while a normal emulator can only tell us the concrete value of out for a given x, Triton can recover the symbolic expression:
((x + 0x1234) * 7) ^ 0x55
For VM devirtualization, the key benefit is that Triton understands CPU instructions. If we can execute the VM interpreter itself, we do not need to manually reimplement each virtual opcode.
Basic Triton Usage
A minimal Triton loop reads bytes at rip, builds an instruction, and lets
Triton process it:
from triton import ARCH, Instruction, TritonContext
ctx = TritonContext(ARCH.X86_64)
pc = ctx.getConcreteRegisterValue(ctx.registers.rip)
inst = Instruction()
inst.setAddress(pc)
inst.setOpcode(ctx.getConcreteMemoryAreaValue(pc, 16))
ctx.processing(inst)
ctx.processing(inst) decodes the instruction, updates concrete state, and
propagates symbolic expressions.
The input buffer can be made symbolic like this:
from triton import CPUSIZE, MemoryAccess
sym = ctx.newSymbolicVariable(64, "x")
ast = ctx.getAstContext()
expr = ctx.newSymbolicExpression(ast.variable(sym), "argv_1")
ctx.assignSymbolicExpressionToMemory(
expr,
MemoryAccess(INPUT_ADDR, CPUSIZE.QWORD),
)
After the native code reads INPUT_ADDR, Triton propagates x through arithmetic,
bit operations, loads, and stores.
To recover the final output expression:
out_ast = ctx.getMemoryAst(MemoryAccess(OUTPUT_ADDR, CPUSIZE.QWORD))
out_ast = ctx.simplify(ast.unroll(out_ast))
The result is a Triton AST. While it is not clean C yet, it already represents the
devirtualized computation. The important shift is that handler semantics come
from the original machine code; the script does not need to know what opcode
0xc7 or 0x2b means.
Using Triton on Challenge-0
The script setup is simple: keep control flow concrete, make the input symbolic, then read the symbolic output.
Why Symbolic Execution Fits This VM
This challenge has no hard, input-dependent VM branch explosion. The bytecode and dispatcher path stay concrete, while the parsed argument is symbolic. The output is a single symbolic 64-bit memory value.
This gives us the best of both worlds:
Concrete control flow + symbolic data flow
This concrete-control, symbolic-data pattern is often enough for arithmetic transforms, encoders, and straight-line VM-protected code.
Loading the ELF
devirt-challenge-0.py starts by mapping every PT_LOAD segment into Triton:
BINARY = Path("./0000/challenge-0")
with BINARY.open("rb") as f:
elf = ELFFile(f)
for segment in elf.iter_segments():
if segment["p_type"] != "PT_LOAD":
continue
vaddr = int(segment["p_vaddr"])
memsz = int(segment["p_memsz"])
data = bytes(segment.data())
data += b"\x00" * (memsz - len(data))
ctx.setConcreteMemoryAreaValue(vaddr, data)
This gives Triton .text, .rodata, .data, and zero-filled memory where
needed.
Creating a Fake Process Context
Instead of running from _start, the script begins execution directly at the VM function:
VM_ENTRY = 0x4006D1
It then sets up enough process state for that function to run:
STACK = 0x7FFF_0000_0000
INPUT = 0x7000_0000_0000
OUTPUT = 0x7000_0000_1000
The ABI registers match the native call:
ctx.setConcreteRegisterValue(regs.rip, VM_ENTRY)
ctx.setConcreteRegisterValue(regs.rsp, STACK_TOP)
ctx.setConcreteRegisterValue(regs.rdi, INPUT)
ctx.setConcreteRegisterValue(regs.rsi, OUTPUT)
The input buffer holds one symbolic 64-bit value:
sym = ctx.newSymbolicVariable(64, "x")
ast = ctx.getAstContext()
expr = ctx.newSymbolicExpression(ast.variable(sym), "argv_1")
ctx.assignSymbolicExpressionToMemory(expr, MemoryAccess(INPUT, CPUSIZE.QWORD))
Not critical in this case, but the VM function also reads fs:0x28, so the isolated setup writes a concrete
canary there:
CANARY_ADDR = 0x28
CANARY = 0xBADC0FFEE0DDF00D
ctx.setConcreteMemoryAreaValue(CANARY_ADDR, CANARY.to_bytes(8, "little"))
Executing the VM with Triton
The execution loop is just native instruction stepping:
for steps in range(1, 100001):
pc = ctx.getConcreteRegisterValue(regs.rip)
if pc in {VM_RET_HANDLER, RET_SENTINEL}:
break
inst = Instruction()
inst.setAddress(pc)
inst.setOpcode(ctx.getConcreteMemoryAreaValue(pc, 16))
ctx.processing(inst)
There is no VM opcode decoder here. The dispatcher, interpolation search, and handlers run as ordinary x86-64 instructions.
For this challenge, Triton reaches the VM return handler after:
39732 native x86-64 instructions
That count includes dispatcher overhead and handler execution.
Recovering the Symbolic Output
After execution stops, the output buffer contains the symbolic expression:
out_ast = ctx.getMemoryAst(MemoryAccess(OUTPUT, CPUSIZE.QWORD))
out_ast = ctx.simplify(ast.unroll(out_ast))
unroll expands internal references; simplify applies Triton’s AST
simplifications. The raw AST is useful for machines, but hard for humans to read:
(bvmul (bvmul ... (bvor (bvshl ...) (bvlshr ...))) ...)

The script has a small AST-to-C printer for the node types needed here:
BVADD -> +
BVSUB -> -
BVMUL -> *
BVAND -> &
BVOR -> |
BVXOR -> ^
BVSHL -> <<
BVLSHR -> >>
CONCAT -> shifts and ors
EXTRACT/ZEXT -> casts and masks
It is not a general C decompiler; it is just a renderer for the recovered expression.
The renderer produces the following devirtualized C code:

Devirtualized Result
With a little manual cleanup, the recovered computation is:
#include <stdint.h>
static inline uint64_t ror64(uint64_t v, unsigned n) {
n &= 63;
return (v >> n) | (v << ((64 - n) & 63));
}
static inline uint64_t challenge_0(uint64_t x) {
uint64_t a = x + UINT64_C(0x34d870d1);
uint64_t b = x | UINT64_C(0x46bc480);
uint64_t n1 = UINT64_C(1) | (a & UINT64_C(7));
uint64_t left = ((b << n1) & UINT64_C(0x3f)) << 4;
uint64_t n2 =
UINT64_C(1) |
((UINT64_C(0x38bca01f) * a) & UINT64_C(0xf));
uint64_t mix = left | ror64(x + UINT64_C(0x1dd9c3c5), n2);
uint64_t tail = (UINT64_C(0xffffffffd9fca98b) | a | x) + a;
return UINT64_C(0x2c7c60b7) * mix * b * tail;
}
Since all operations use unsigned 64-bit arithmetic, overflows wrap modulo 2^64.
Checking the Result
Compile and run the devirtualized function:
int main(int argc, char** argv) {
uint64_t input = strtoull(argv[1], NULL, 10);
uint64_t output = challenge_0(input);
printf("%lu\n", output);
}

Triton deobfuscation script
#!/usr/bin/env python3
from __future__ import annotations
import sys
from pathlib import Path
from elftools.elf.elffile import ELFFile
from triton import ARCH, AST_NODE, CPUSIZE, Instruction, MemoryAccess, MODE, TritonContext
BINARY = Path("tigress-challenges/0000/challenge-0")
if len(sys.argv) > 1:
BINARY = Path(sys.argv[1])
VM_ENTRY = 0x4006D1
VM_RET_HANDLER = 0x400C35
STACK = 0x7FFF_0000_0000
STACK_SIZE = 0x20000
STACK_TOP = STACK + STACK_SIZE - 0x100
RET_SENTINEL = 0x4141_4141_4141_4141
INPUT = 0x7000_0000_0000
OUTPUT = 0x7000_0000_1000
CANARY_ADDR = 0x28
CANARY = 0xBADC0FFEE0DDF00D
def ast_to_c(node: object) -> tuple[str, int, int | None]:
ty = node.getType()
children = node.getChildren()
def integer(child: object) -> int:
return int(child.getInteger())
def c_const(value: int, bits: int) -> tuple[str, int, int]:
value &= (1 << bits) - 1
if bits == 64:
return f"UINT64_C(0x{value:x})", bits, value
return f"0x{value:x}", bits, value
if ty == AST_NODE.BV:
return c_const(integer(children[0]), integer(children[1]))
if ty == AST_NODE.VARIABLE:
sym = node.getSymbolicVariable()
return sym.getAlias() or sym.getName(), sym.getBitSize(), None
if ty == AST_NODE.CONCAT:
parts = [ast_to_c(child) for child in children]
bits = sum(part_bits for _text, part_bits, _const in parts)
if all(part_const is not None for _text, _bits, part_const in parts):
value = 0
for _text, part_bits, part_const in parts:
value = (value << part_bits) | int(part_const)
return c_const(value, bits)
expr = "0"
for text, part_bits, _const in parts:
expr = f"(({expr} << {part_bits}) | ({text}))"
return expr, bits, None
if ty == AST_NODE.EXTRACT:
high = integer(children[0])
low = integer(children[1])
text, _src_bits, value = ast_to_c(children[2])
bits = high - low + 1
mask = (1 << bits) - 1
if value is not None:
return c_const((value >> low) & mask, bits)
if low == 0 and high == 7:
return f"((uint8_t)({text}))", bits, None
return f"(({text} >> {low}) & 0x{mask:x})", bits, None
if ty == AST_NODE.ZX:
extra = integer(children[0])
text, bits, value = ast_to_c(children[1])
bits += extra
if value is not None:
return c_const(value, bits)
if bits == 64:
return f"((uint64_t)({text}))", bits, None
return f"({text})", bits, None
binary_ops = {
AST_NODE.BVADD: ("+", lambda a, b: a + b),
AST_NODE.BVSUB: ("-", lambda a, b: a - b),
AST_NODE.BVMUL: ("*", lambda a, b: a * b),
AST_NODE.BVAND: ("&", lambda a, b: a & b),
AST_NODE.BVOR: ("|", lambda a, b: a | b),
AST_NODE.BVXOR: ("^", lambda a, b: a ^ b),
}
if ty in binary_ops:
op, fold = binary_ops[ty]
left_text, left_bits, left_value = ast_to_c(children[0])
right_text, right_bits, right_value = ast_to_c(children[1])
bits = max(left_bits, right_bits)
if left_value is not None and right_value is not None:
return c_const(fold(left_value, right_value), bits)
return f"({left_text} {op} {right_text})", bits, None
if ty in {AST_NODE.BVSHL, AST_NODE.BVLSHR}:
op = "<<" if ty == AST_NODE.BVSHL else ">>"
left_text, left_bits, left_value = ast_to_c(children[0])
right_text, _right_bits, right_value = ast_to_c(children[1])
if left_value is not None and right_value is not None:
count = right_value & (left_bits - 1)
if ty == AST_NODE.BVSHL:
return c_const(left_value << count, left_bits)
return c_const(left_value >> count, left_bits)
return f"({left_text} {op} {right_text})", left_bits, None
raise NotImplementedError(f"unsupported Triton AST node: {ty}: {node}")
ctx = TritonContext(ARCH.X86_64)
ctx.setMode(MODE.ALIGNED_MEMORY, True)
ctx.setMode(MODE.AST_OPTIMIZATIONS, True)
with BINARY.open("rb") as f:
elf = ELFFile(f)
for segment in elf.iter_segments():
if segment["p_type"] != "PT_LOAD":
continue
vaddr = int(segment["p_vaddr"])
memsz = int(segment["p_memsz"])
data = bytes(segment.data())
data += b"\x00" * (memsz - len(data))
ctx.setConcreteMemoryAreaValue(vaddr, data)
ctx.setConcreteMemoryAreaValue(STACK, b"\x00" * STACK_SIZE)
ctx.setConcreteMemoryAreaValue(INPUT, b"\x00" * 0x1000)
ctx.setConcreteMemoryAreaValue(OUTPUT, b"\x00" * 0x1000)
ctx.setConcreteMemoryAreaValue(CANARY_ADDR, CANARY.to_bytes(8, "little"))
ctx.setConcreteMemoryAreaValue(STACK_TOP, RET_SENTINEL.to_bytes(8, "little"))
ast = ctx.getAstContext()
sym = ctx.newSymbolicVariable(64, "x")
expr = ctx.newSymbolicExpression(ast.variable(sym), "argv_1")
ctx.assignSymbolicExpressionToMemory(expr, MemoryAccess(INPUT, CPUSIZE.QWORD))
regs = ctx.registers
ctx.setConcreteRegisterValue(regs.rip, VM_ENTRY)
ctx.setConcreteRegisterValue(regs.rsp, STACK_TOP)
ctx.setConcreteRegisterValue(regs.rbp, 0)
ctx.setConcreteRegisterValue(regs.rbx, 0)
ctx.setConcreteRegisterValue(regs.rdi, INPUT)
ctx.setConcreteRegisterValue(regs.rsi, OUTPUT)
for steps in range(1, 100001):
pc = ctx.getConcreteRegisterValue(regs.rip)
if pc in {VM_RET_HANDLER, RET_SENTINEL}:
break
inst = Instruction()
inst.setAddress(pc)
inst.setOpcode(ctx.getConcreteMemoryAreaValue(pc, 16))
ctx.processing(inst)
if inst.getSize() == 0:
raise RuntimeError(f"Triton could not decode instruction at {pc:#x}")
else:
raise RuntimeError("VM did not reach the return handler")
out_ast = ctx.getMemoryAst(MemoryAccess(OUTPUT, CPUSIZE.QWORD))
out_ast = ctx.simplify(ast.unroll(out_ast))
c_expr, _bits, _value = ast_to_c(out_ast)
print(f"Triton executed {steps} native instructions.")
print(f"Simplified output AST: {out_ast}")
print()
print("#include <stdint.h>")
print()
print("static inline uint64_t challenge_0(uint64_t x) {")
print(f" return {c_expr};")
print("}")
Devirtualized C source
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
static inline uint64_t ror64(uint64_t v, unsigned n) {
n &= 63;
return (v >> n) | (v << ((64 - n) & 63));
}
static inline uint64_t challenge_0(uint64_t x) {
uint64_t a = x + UINT64_C(0x34d870d1);
uint64_t b = x | UINT64_C(0x46bc480);
uint64_t n1 = UINT64_C(1) | (a & UINT64_C(7));
uint64_t left = ((b << n1) & UINT64_C(0x3f)) << 4;
uint64_t n2 =
UINT64_C(1) |
((UINT64_C(0x38bca01f) * a) & UINT64_C(0xf));
uint64_t mix = left | ror64(x + UINT64_C(0x1dd9c3c5), n2);
uint64_t tail = (UINT64_C(0xffffffffd9fca98b) | a | x) + a;
return UINT64_C(0x2c7c60b7) * mix * b * tail;
}
int main(int argc, char** argv) {
uint64_t input = strtoull(argv[1], NULL, 10);
uint64_t output = challenge_0(input);
printf("%lu\n", output);
}